自连接查询
为什么需要自连接
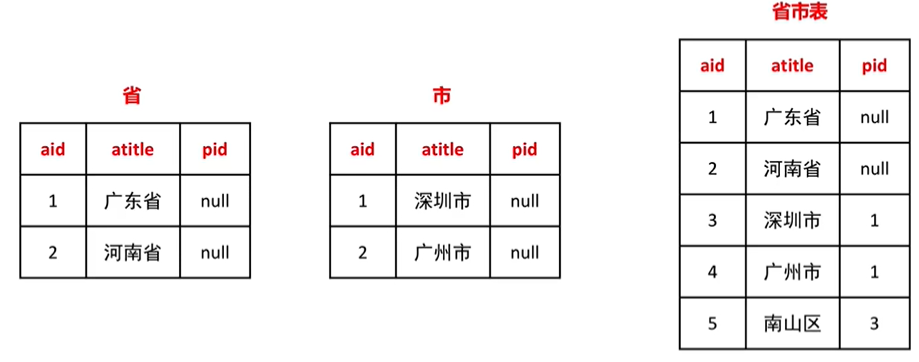
需求:要查询广东省下的所有市,如果分两张表进行存储,那查询会涉及两张表的查询(省表和市表),会降低查询效率。而如果把它存储在一张表中(省市表),使用自连接查询,会加快查询速度,减少数据表占用的空间。
自连接本质是:同一张表在同一个查询里“出现两次”,分别扮演不同角色(子节点/父节点、员工/领导等),因此必须使用表别名区分。
自连接如何查询
- 获取广东省的aid(aid=1)
- 获取pid为1的所有atitle
自连接
分别给省市表起一个别名city和province.
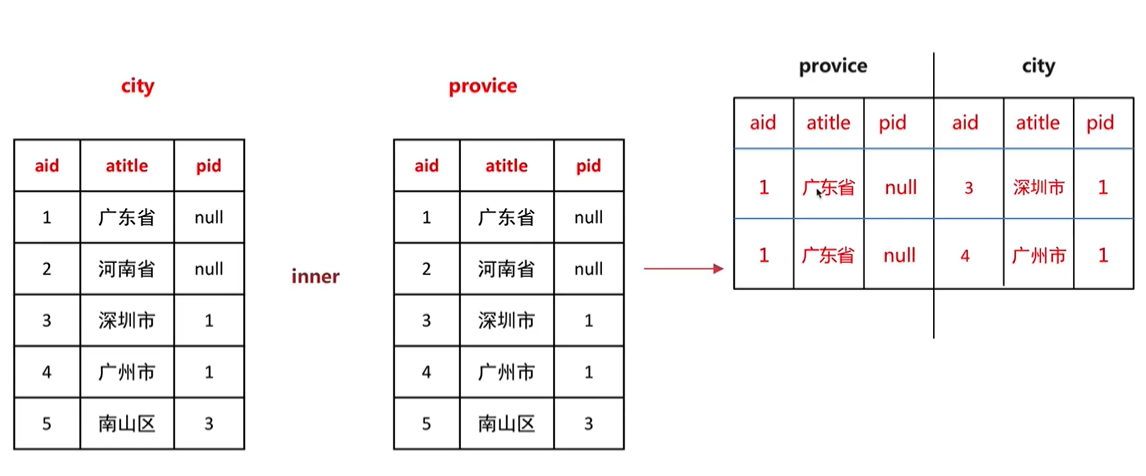
select city.* from
areas as city
inner join
areas as province
on city.pid = province.aid
where province.atitle = '广东省';
常见变体:把父节点信息一并查出来
SELECT
city.atitle AS city_name,
province.atitle AS province_name
FROM areas AS city
INNER JOIN areas AS province ON city.pid = province.aid
WHERE province.atitle = '广东省';
适用场景与替代建模
- 适用:一层或少量层级的父子关系查询(省/市、部门/子部门、员工/直属领导)
- 替代:层级很深、需要一次性查整棵树时,自连接会变得复杂;可考虑 MySQL 8 的递归 CTE,或用闭包表/路径枚举等数据建模方式